
Everyone in financial services talks about resilience. We have DR plans, architecture diagrams, dashboards, and increasingly, tools like AWS Resilience Hub. On paper, it all looks good. In practice, most resilience programs don’t fail because of missing tooling — they fail because they never move beyond isolated assessments.
A team runs a Resilience Hub assessment. They get a score. Maybe they even fix a few findings. And then nothing happens. No aggregation. No cadence. No program. Just a snapshot that lives in one account, attached to one application, reviewed once.
I’ve seen this pattern enough times in financial services to know it’s not a tooling problem. It’s an organizational one. And if you want resilience that actually means something, you have to confront it directly.
Resilience Doesn’t Live in One Account
Modern financial systems don’t live in one place. They span line-of-business accounts, shared platform layers, data environments, and third-party dependencies. The critical user journeys — payments, trades, claims — cut across all of them.
Yet Resilience Hub is typically deployed against one app, in one account, with one assessment. That’s not resilience. That’s local optimization pretending to be a program.
As outlined in the Building Resilient Financial Services whitepaper, resilience must be measurable and demonstrable across interconnected services, not evaluated in isolation. A payment flow that touches API Gateway in one account, a processing Lambda in a shared services account, and DynamoDB in a data account doesn’t care that each of those components passed its individual resilience check. What matters is whether the flow as a whole can survive failure.
This is the gap Resilience Hub doesn’t close on its own. It was designed to evaluate applications, not programs. If you want the latter, you have to build it.
The Pattern That Actually Works: Hub-and-Spoke
If you want to scale resilience, you need to treat it like a distributed measurement system. Each account owns its applications and runs its own assessments. But the program — the aggregation, the scoring, the trend analysis — lives centrally.
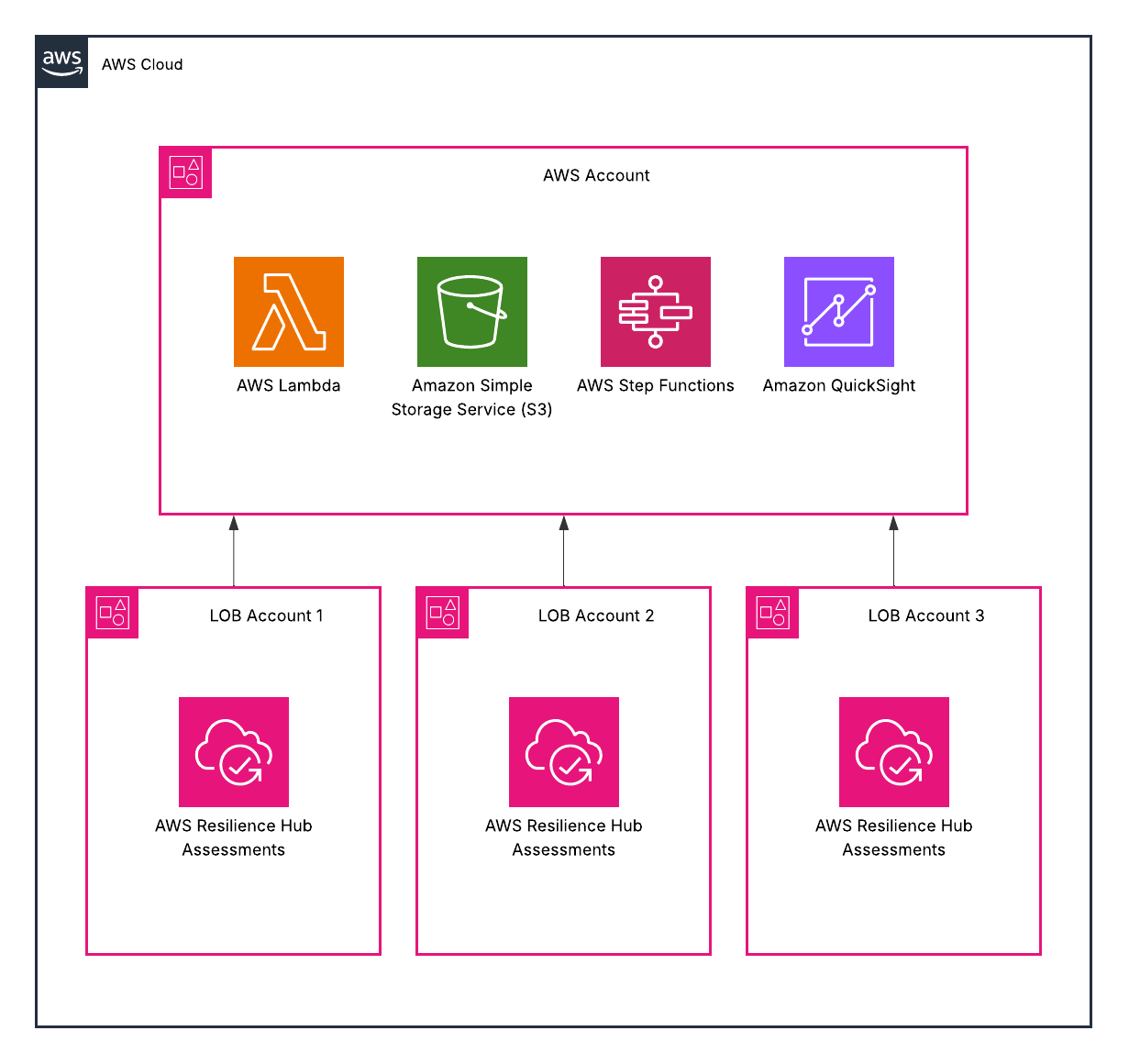
This isn’t complicated architecture. It’s a standard IAM role in each spoke account that a central account can assume, a scheduled Lambda or Step Functions workflow that pulls assessment data across accounts and normalizes the structure, a data store in S3 or DynamoDB that tracks history (not just current state), and a dashboard layer — QuickSight or whatever your organization already uses — tied to critical services and business impact.
The hard part isn’t building it. The hard part is getting the organizational agreement that resilience data should flow centrally in the first place.
Resilience Hub Is a Data Source, Not a Dashboard
This is where I think most teams go wrong. They use Resilience Hub as a dashboard — open the console, look at the score, maybe screenshot it for a quarterly review. That’s underutilizing it significantly.
Resilience Hub is a modeling engine, a policy evaluator, and a scoring system. It is not your enterprise view, your governance layer, or your program. The real value emerges when you stop looking at the UI and start treating it as a data source.
The API surface is small and that’s a good thing:
client.list_apps()
client.list_app_assessments()
client.describe_app_assessment()
From those three calls, you can build enterprise-wide resilience scoring, trend analysis over time, drift detection across environments, and audit evidence tied to real systems. The UI tells you what happened once. The API lets you prove improvement over time — and that’s what regulators actually care about.
Where This Connects to Program Cadence
This is the part most organizations completely miss. Resilience is not a tool, a dashboard, or a quarterly checkbox. It’s a cadence.
I keep coming back to this when working with financial services clients: the difference between organizations that have a resilience program and organizations that have a resilience report is whether they review on a regular cadence and actually act on what they find.
| Cadence | What actually happens |
|---|---|
| Weekly | Pull Resilience Hub data, detect drift |
| Monthly | Review resilience posture across services |
| Quarterly | Validate against real scenarios |
| Continuous | Track improvement and regressions |
Monthly reviews. Quarterly scenario testing. Continuous improvement loops. If you’re not doing these, you don’t have a program — you have a document that says you do.
From Assessment to Evidence
Regulators don’t care about your architecture diagrams. They care about whether services stay within tolerance, whether failures are tested, and whether you improve over time. These aren’t unreasonable asks, but they require evidence that most organizations can’t produce because they never built the infrastructure to collect it.
A multi-account Resilience Hub strategy gives you centralized visibility across distributed systems, consistent measurement aligned to business services, and — critically — evidence you can actually defend when someone asks how you know your systems are resilient.
Most organizations never make this leap. They run assessments, fix findings, and move on. But resilience doesn’t scale that way. It scales when you treat it as a system — measured continuously, aggregated centrally, and reviewed on a cadence.
AWS Resilience Hub gives you the raw signal. What you build around it determines whether you have a tool or a capability.