Introduction
On August 1, 2012, Knight Capital Group—one of the largest market makers on the New York Stock Exchange—lost $440 million in 45 minutes due to a software deployment failure. The incident nearly bankrupted the firm and sent shockwaves through financial markets. While the technical details are fascinating, the real lesson lies in what wasn’t there: an effective, centralized mechanism to stop runaway automation before catastrophic losses occurred.
This post explores how modern streaming architectures using Apache Kafka and Apache Spark can implement the kind of real-time risk controls that regulations now require—and that Knight Capital desperately needed. We’ll connect the dots between a historic trading disaster, regulatory requirements, and a hands-on demo you can deploy yourself.
The Knight Capital Incident: What Happened?
On that August morning, Knight Capital deployed new trading software to eight servers. Due to an operational error, one server retained old code that had been repurposed. When the market opened, this server began executing a dormant algorithm called “Power Peg” that was never meant to run in production.
The result was catastrophic:
- The algorithm sent millions of unintended orders to the market
- Knight accumulated massive, unwanted positions in 154 stocks
- The firm lost $440 million in approximately 45 minutes
- Knight Capital required a $400 million emergency bailout to survive
The Core Failure Modes
Several factors contributed to the disaster:
- Partial Deployment: Not all servers received the correct code update
- Lack of Centralized Control: No single point could halt all trading activity
- Insufficient Pre-Trade Controls: Orders weren’t validated against risk limits before execution
- Delayed Detection: The problem wasn’t identified and stopped quickly enough
The Knight Capital incident wasn’t just a software bug—it was a systems design failure. The firm lacked the architectural patterns needed to maintain “direct and exclusive control” over its market access, a concept that would soon become central to regulatory requirements.
Enter SEC Rule 15c3-5: The Market Access Rule
In response to concerns about the risks posed by direct market access and algorithmic trading, the SEC adopted Rule 15c3-5 in November 2010 (before the Knight incident, though Knight’s failure validated the rule’s necessity).
What is Market Access?
Market access refers to the ability to send orders directly to exchanges or alternative trading systems. Broker-dealers that provide market access—whether for their own trading or for customers—act as gatekeepers to the markets.
What the Rule Requires
SEC Rule 15c3-5, formally titled “Risk Management Controls for Brokers or Dealers with Market Access,” requires broker-dealers to:
Implement Risk Management Controls: Establish, document, and maintain a system of risk management controls and supervisory procedures reasonably designed to manage the financial, regulatory, and other risks of market access.
Pre-Trade Controls: Implement controls that prevent the entry of orders that exceed appropriate pre-set credit or capital thresholds, or that appear to be erroneous.
Direct and Exclusive Control: Broker-dealers must have “direct and exclusive control” over the technology that provides market access. This means they cannot delegate control to customers or third parties—they must retain the ability to stop trading immediately.
Regular Review: Controls must be reviewed and tested regularly to ensure they’re working as intended.
The “Direct and Exclusive Control” Concept
This phrase is critical. It means:
- The broker-dealer must be able to disable or limit market access immediately
- Control cannot be delegated to customers or outsourced
- There must be a centralized mechanism to enforce risk limits
- The firm must maintain supervisory procedures over all market access
The rule doesn’t prescribe specific technologies (it doesn’t say “you must use Kafka”), but it does mandate capabilities that modern streaming architectures are well-suited to provide.
Regulatory Text
From the SEC’s adopting release:
“The rule requires a broker-dealer with market access to establish, document, and maintain a system of risk management controls and supervisory procedures reasonably designed to manage the financial, regulatory, and other risks of this business activity.”
The rule specifically addresses:
- Financial risk management (credit and capital thresholds)
- Regulatory risk management (compliance with regulatory requirements)
- Erroneous order controls (preventing clearly erroneous orders from reaching the market)
Connecting Regulation to Architecture
Let’s translate regulatory requirements into architectural patterns:
| Regulatory Requirement | Architectural Pattern | Our Demo Implementation |
|---|---|---|
| Direct and exclusive control | Centralized kill switch with authoritative state | Kafka compacted topic for kill state |
| Pre-trade risk controls | Real-time order validation before routing | Order router checks kill state |
| Prevent erroneous orders | Automated detection of anomalous patterns | Spark streaming detects threshold breaches |
| Supervisory procedures | Audit trail and manual override capability | Audit topic + operator console API |
| Regular review and testing | Observable, testable system | CloudWatch dashboards + demo scripts |
The key insight: Separation of concerns between detection and enforcement.
- Detection (Spark): Analyzes order patterns, computes risk signals, may suggest kill actions
- Enforcement (Router): Makes the final decision on every order based on authoritative state
- Control Plane (Kill Switch): Maintains single source of truth for kill status
- Audit (Kafka + DynamoDB): Immutable record of all decisions
This separation ensures that even if detection fails or is delayed, enforcement remains consistent. The kill switch state is authoritative and replayable.
Why Kafka Compaction for Kill State?
One of the most interesting architectural choices in our demo is using a Kafka compacted topic for kill switch state. Here’s why:
The Problem
We need a “configuration” or “state” that:
- Is the single source of truth
- Can be updated in real-time
- Is immediately available to all consumers
- Has a complete audit trail
- Can be replayed to bootstrap new services
The Solution: Log Compaction
Kafka’s log compaction retains the latest value for each key while preserving the full history of changes. For kill switch state:
Compaction Example:
Commands Topic (Full History):
ACCOUNT:12345 KILL t=100
ACCOUNT:12345 UNKILL t=200
ACCOUNT:12345 KILL t=300
State Topic (Compacted - Latest Only):
ACCOUNT:12345 KILL t=300
How it works:
- Key: Scope (e.g., “ACCOUNT:12345”, “SYMBOL:AAPL”, “GLOBAL”)
- Value: Current status (KILLED or ACTIVE) with metadata
- Compaction: Kafka automatically retains only the latest state per scope
- Replayability: New consumers can read the entire topic to bootstrap current state
This gives us:
- Single source of truth: The compacted topic is authoritative
- Fast bootstrap: New routers can quickly load all current kill states
- Audit trail: The commands topic retains full history
- Distributed config: No need for external config store
State Compaction Process
The following sequence diagram illustrates how Kafka’s log compaction maintains the latest state per scope:
sequenceDiagram
participant K1 as Kafka<br/>killswitch.commands.v1<br/>(Full History)
participant KSA as Kill Switch<br/>Aggregator
participant K2 as Kafka<br/>killswitch.state.v1<br/>(Compacted)
participant KC as Kafka<br/>Compaction Process
participant OR as Order Router<br/>(New Instance)
Note over K1,OR: State Evolution Over Time
Note over K1: t=100
K1->>KSA: KILL command<br/>ACCOUNT:12345
KSA->>K2: Publish state<br/>Key: ACCOUNT:12345<br/>Value: KILLED (t=100)
Note over K1: t=200
K1->>KSA: UNKILL command<br/>ACCOUNT:12345
KSA->>K2: Publish state<br/>Key: ACCOUNT:12345<br/>Value: ACTIVE (t=200)
Note over K1: t=300
K1->>KSA: KILL command<br/>ACCOUNT:12345
KSA->>K2: Publish state<br/>Key: ACCOUNT:12345<br/>Value: KILLED (t=300)
Note over K2: Before Compaction:<br/>ACCOUNT:12345 KILLED (t=100)<br/>ACCOUNT:12345 ACTIVE (t=200)<br/>ACCOUNT:12345 KILLED (t=300)
K2->>KC: Compaction triggered<br/>(based on segment.ms<br/>and dirty ratio)
KC->>KC: Retain latest value<br/>per key
Note over K2: After Compaction:<br/>ACCOUNT:12345 KILLED (t=300)<br/>(older values removed)
Note over OR: New router starts up
OR->>K2: Read from beginning
K2-->>OR: ACCOUNT:12345 = KILLED (t=300)
Note over OR: Router bootstrapped<br/>with current state<br/>(fast, no history to read)
Note over K1: Commands topic still has<br/>full history for audit
Compaction Configuration
cleanup.policy=compact
min.cleanable.dirty.ratio=0.01 # Compact frequently
segment.ms=60000 # Small segments for faster compaction
These settings ensure kill state updates propagate quickly while maintaining the full history in the commands topic.
Demo Architecture Walkthrough
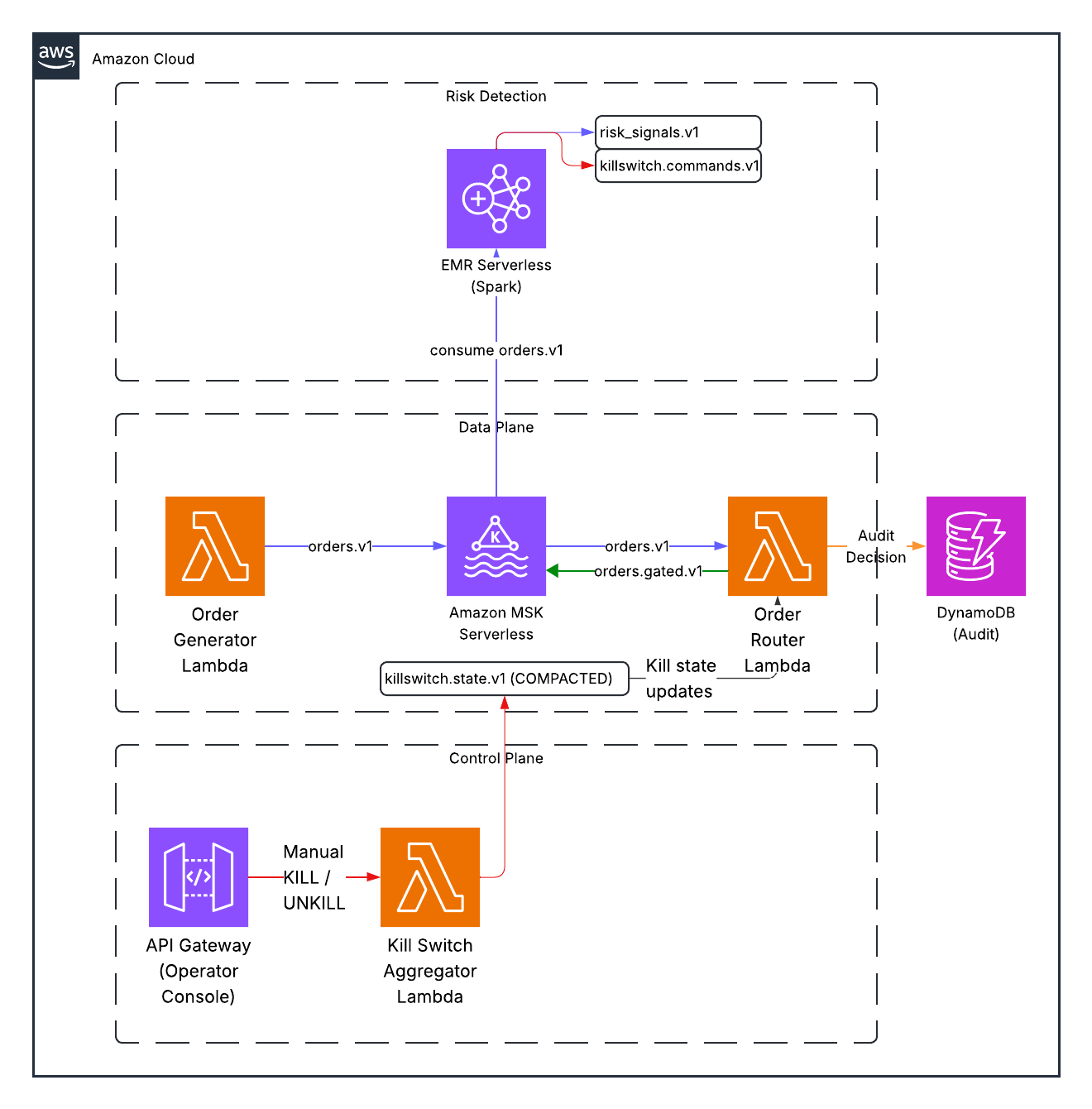
Our demo implements these patterns using serverless AWS services:
Key architectural decisions mapped to regulatory requirements:
| Requirement | Implementation |
|---|---|
| Direct and exclusive control | Operator Console API with manual override capability |
| Pre-trade risk controls | Order Router checks kill state before routing every order |
| Prevent erroneous orders | Spark detects anomalous patterns in real-time |
| Audit trail | Immutable Kafka log + DynamoDB index for queries |
| Supervisory procedures | Documented thresholds, operator actions, correlation IDs |
Normal Order Flow
The following sequence diagram illustrates how orders flow through the system when no kill switches are active:
sequenceDiagram
participant OG as Order Generator<br/>(Lambda)
participant K1 as Kafka<br/>orders.v1
participant S as Spark<br/>Risk Detector
participant K2 as Kafka<br/>risk_signals.v1
participant OR as Order Router<br/>(Lambda)
participant KS as Kafka<br/>killswitch.state.v1
participant K3 as Kafka<br/>orders.gated.v1
participant K4 as Kafka<br/>audit.v1
participant DDB as DynamoDB<br/>Audit Index
Note over OG,DDB: Normal Operation - No Kill Switches Active
OG->>K1: Publish order<br/>(5 orders/sec)
Note right of K1: Key: account_id<br/>Partition by account
K1->>S: Consume orders
S->>S: Compute 60s window<br/>order_count = 50<br/>notional = $500K
Note right of S: Below thresholds:<br/>order_rate < 100<br/>notional < $1M
S->>K2: Publish risk signal<br/>(metrics only, no alert)
K1->>OR: Consume order
OR->>KS: Check kill state<br/>for ACCOUNT:12345
KS-->>OR: No kill state found<br/>(ACTIVE by default)
Note over OR: Decision: ALLOW
OR->>K3: Forward order<br/>to gated topic
OR->>K4: Publish audit event<br/>decision=ALLOW
OR->>DDB: Write audit record<br/>(async, best effort)
Note over OG,DDB: Order successfully routed
Topic Flow
- orders.v1: Raw orders from generator
- risk_signals.v1: Windowed aggregations from Spark (order rate, notional, concentration)
- killswitch.commands.v1: Kill/unkill commands (from Spark or operator)
- killswitch.state.v1: Authoritative kill state (compacted)
- orders.gated.v1: Orders that passed kill switch check
- audit.v1: Immutable audit trail of all routing decisions
Order Router Enforcement
The following diagram shows the detailed logic of how the order router enforces kill switches:
sequenceDiagram
participant K1 as Kafka<br/>orders.v1
participant OR as Order Router<br/>(Lambda)
participant Cache as In-Memory<br/>Kill State Cache
participant K2 as Kafka<br/>killswitch.state.v1
participant K3 as Kafka<br/>orders.gated.v1
participant K4 as Kafka<br/>audit.v1
participant DDB as DynamoDB<br/>Audit Index
Note over K1,DDB: Order Router Processing Logic
K1->>OR: Consume order<br/>account_id: 12345<br/>symbol: AAPL
OR->>Cache: Check kill state<br/>for scopes
Note over Cache: Check hierarchy:<br/>1. GLOBAL<br/>2. ACCOUNT:12345<br/>3. SYMBOL:AAPL
alt GLOBAL kill active
Cache-->>OR: GLOBAL = KILLED
Note over OR: Decision: DROP<br/>Reason: Global kill
else ACCOUNT kill active
Cache-->>OR: ACCOUNT:12345 = KILLED
Note over OR: Decision: DROP<br/>Reason: Account kill
else SYMBOL kill active
Cache-->>OR: SYMBOL:AAPL = KILLED
Note over OR: Decision: DROP<br/>Reason: Symbol kill
else No kills active
Cache-->>OR: All scopes ACTIVE
Note over OR: Decision: ALLOW
OR->>K3: Forward order
end
OR->>K4: Publish audit event<br/>decision: ALLOW/DROP<br/>scope_matches: [...]<br/>corr_id: uuid-789
OR->>DDB: Write audit record<br/>(async, best effort)
Note over K2,OR: State updates arrive
K2->>OR: New state update
OR->>Cache: Update in-memory cache
Note over Cache: Cache always reflects<br/>latest compacted state
Latency Considerations
This design introduces additional latency relative to in-process risk checks. However, it provides centralized, authoritative enforcement and replayable state — properties essential for satisfying the “direct and exclusive control” requirement of SEC Rule 15c3-5.
In most retail and DMA (Direct Market Access) environments, the added milliseconds (approximately 50ms at most) are an acceptable tradeoff for deterministic control and auditability. This approach is not intended to reflect the architecture of any former employer but rather examines how brokerages can solve these regulatory challenges in a robust, scalable way.
Kill Switch Activation Sequence
Here’s what happens when Spark detects a threshold breach:
sequenceDiagram
participant OG as Order Generator<br/>(Lambda)
participant K1 as Kafka<br/>orders.v1
participant S as Spark<br/>Risk Detector
participant K2 as Kafka<br/>risk_signals.v1
participant K3 as Kafka<br/>killswitch.commands.v1
participant KSA as Kill Switch<br/>Aggregator (Lambda)
participant K4 as Kafka<br/>killswitch.state.v1
participant DDB as DynamoDB<br/>State Cache
participant OR as Order Router<br/>(Lambda)
participant K5 as Kafka<br/>audit.v1
Note over OG,K5: Panic Mode Triggered
OG->>K1: Publish orders<br/>(50 orders/sec)
Note right of K1: High rate for<br/>ACCOUNT:12345
K1->>S: Consume orders
S->>S: Compute 60s window<br/>order_count = 150<br/>notional = $2.5M
Note over S: BREACH DETECTED!<br/>order_count > 100
S->>K2: Publish risk signal<br/>with breach flag
S->>K3: Publish KILL command<br/>scope: ACCOUNT:12345<br/>reason: "Order rate breach"<br/>corr_id: uuid-123
Note over K3: Commands topic<br/>(full history retained)
K3->>KSA: Consume KILL command
KSA->>KSA: Process command<br/>Create state record
KSA->>K4: Publish state<br/>Key: ACCOUNT:12345<br/>Value: KILLED<br/>corr_id: uuid-123
Note right of K4: Compacted topic<br/>(latest state per key)
KSA->>DDB: Update state cache<br/>(optional, for fast lookup)
Note over K4,OR: State propagates to all routers
K4->>OR: Router reads state update
OR->>OR: Update in-memory cache<br/>ACCOUNT:12345 = KILLED
K1->>OR: New order from 12345
OR->>OR: Check kill state<br/>ACCOUNT:12345 = KILLED
Note over OR: Decision: DROP
OR->>K5: Publish audit event<br/>decision=DROP<br/>reason: "Kill switch active"<br/>corr_id: uuid-123
Note over OG,K5: Order blocked - Kill switch active
Key observations:
- Detection (Spark) is decoupled from enforcement (Router)
- State updates flow through compacted topic (single source of truth)
- Every decision is audited with correlation IDs
- Manual override capability (operator can unkill)
Spark SQL for Risk Detection
The Spark job uses Spark SQL for windowed aggregations:
SELECT
window(event_time, '60 seconds') as window,
account_id,
COUNT(*) as order_count,
SUM(qty * price) as total_notional,
COUNT(DISTINCT symbol) as unique_symbols
FROM orders
GROUP BY window(event_time, '60 seconds'), account_id
When thresholds are breached, Spark emits a kill command:
{
"cmd_id": "uuid",
"scope": "ACCOUNT:12345",
"action": "KILL",
"reason": "Order rate breach: 150 orders in 60s",
"triggered_by": "spark",
"metric": "order_rate_60s",
"value": 150
}
Enforcement Logic
The order router maintains an in-memory cache of kill state (bootstrapped from the compacted topic) and checks every order:
def check_kill_status(order):
scopes = [
'GLOBAL',
f'ACCOUNT:{order["account_id"]}',
f'SYMBOL:{order["symbol"]}'
]
for scope in scopes:
if scope in kill_state and kill_state[scope]['status'] == 'KILLED':
return True, scope, kill_state[scope]['reason']
return False, None, None
Every decision is audited with correlation IDs for traceability.
Alternative Approaches for High-Frequency Trading
For high-frequency trading environments, the architecture described above would introduce unacceptable latency. In these ultra-low-latency scenarios, the pre-trade risk gate would be embedded directly in the order handling process—potentially implemented in hardware (e.g., FPGA)—to ensure deterministic, microsecond-level enforcement without introducing network or broker latency.
Key differences in HFT implementations:
- Embedded Controls: Risk checks directly in the order path, not as external services
- Hardware Acceleration: FPGAs or dedicated ASICs for microsecond-level checks
- Local State: State maintained in local memory with minimal or no network calls
- Minimal Serialization: Custom binary protocols instead of JSON
- Deterministic Performance: Bounded, predictable latency for all operations
In such environments, you wouldn’t add Kafka to the hot path, as even the most optimized message broker would introduce unacceptable latency. Instead, while still maintaining the regulatory requirements for “direct and exclusive control,” risk configurations would be loaded at startup and updated via side channels, with enforcement happening directly within the order processing pipeline.
Why This Matters for Students
This demo teaches several critical concepts:
- Event-Driven Architecture: Using Kafka as the backbone for real-time systems
- Stream Processing: Spark Structured Streaming for windowed aggregations
- Separation of Concerns: Detection vs. enforcement vs. control
- Operational Patterns: Compaction, idempotency, correlation IDs
- Regulatory Thinking: How compliance requirements shape architecture
- Serverless at Scale: Building production-grade systems without managing servers
Most importantly, it connects abstract concepts (regulations, risk management) to concrete implementations you can deploy and experiment with.
Try It Yourself
The complete demo is available in the repository. You can:
- Deploy to AWS: Full serverless stack with Terraform
- Run locally: Docker Compose for quick iteration
- Experiment: Change thresholds, add new scopes, implement throttling
- Learn: Detailed workshop docs with exercises
See the repository for step-by-step instructions.
Suggested Exercises
- Add a SYMBOL-level kill switch that triggers on concentration
- Implement throttling (rate limiting) instead of binary kill/allow
- Add deduplication to prevent duplicate order IDs
- Build a dashboard to visualize risk signals in real-time
- Implement automatic unkill after a cooldown period
Conclusion
The Knight Capital incident taught the industry a painful lesson about the importance of centralized control and pre-trade risk management. SEC Rule 15c3-5 codified these lessons into regulatory requirements that all broker-dealers must follow.
Modern streaming architectures using Kafka and Spark provide elegant solutions to these requirements:
- Kafka’s compacted topics give us authoritative, replayable state
- Spark’s streaming SQL enables real-time risk detection
- Separation of detection and enforcement ensures consistent control
- Immutable audit trails provide full traceability
While this demo uses synthetic data and simplified logic, the architectural patterns are production-grade. Real broker-dealers use similar approaches to maintain the “direct and exclusive control” that regulations require and that Knight Capital lacked.
The next time you hear about a trading glitch or market disruption, ask: “Where was the kill switch?”
Sources and Further Reading
Primary Regulatory Sources
SEC Rule 15c3-5 Final Adopting Release
Securities and Exchange Commission, Release No. 34-63241 (November 3, 2010)
https://www.sec.gov/files/rules/final/2010/34-63241.pdfSEC Small Entity Compliance Guide for Rule 15c3-5
https://www.sec.gov/files/rules/final/2010/34-63241-secg.htmCode of Federal Regulations: 17 CFR § 240.15c3-5
https://www.law.cornell.edu/cfr/text/17/240.15c3-5
Knight Capital Incident
SEC Administrative Proceeding Against Knight Capital
File No. 3-15570 (October 16, 2013)
Details the regulatory findings and penalties related to the incident.Nanex Research: Knight Capital’s Trading Glitch
Technical analysis of the order flow during the incident (secondary source).
Technical Resources
Apache Kafka Documentation: Log Compaction
https://kafka.apache.org/documentation/#compactionApache Spark Structured Streaming Guide
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Disclaimer: This blog post and associated demo are for educational purposes only. They do not constitute trading advice, legal advice, or compliance guidance. The architecture described does not represent any former employer’s actual systems or implementations. The demo uses synthetic data and simplified logic to illustrate concepts rather than real production implementations. Actual production trading systems require extensive additional controls, testing, and regulatory review. Always consult with legal and compliance professionals when implementing market access systems.